Chinese Lipreading with RNN
29 Jun 2018(This is a brief summary of my undergraduate thesis project, which has won an university-level excellence award.)
Feature of my thesis
-
Migrating cutting-edge lipreading research results to Chinese lipreading practice
The lipreading methodology is greately inspired by the following article:
Wand, Michael, Jan Koutník, and Jürgen Schmidhuber. “Lipreading with long short-term memory.” Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on. IEEE, 2016.
- Proposing a valid automatic lip feature segmentation method that allows the lipreading system to operate on real world problems
- The experiment confirms that the system functions well on a small-scale real world Chinese lipreading problem
System architecture
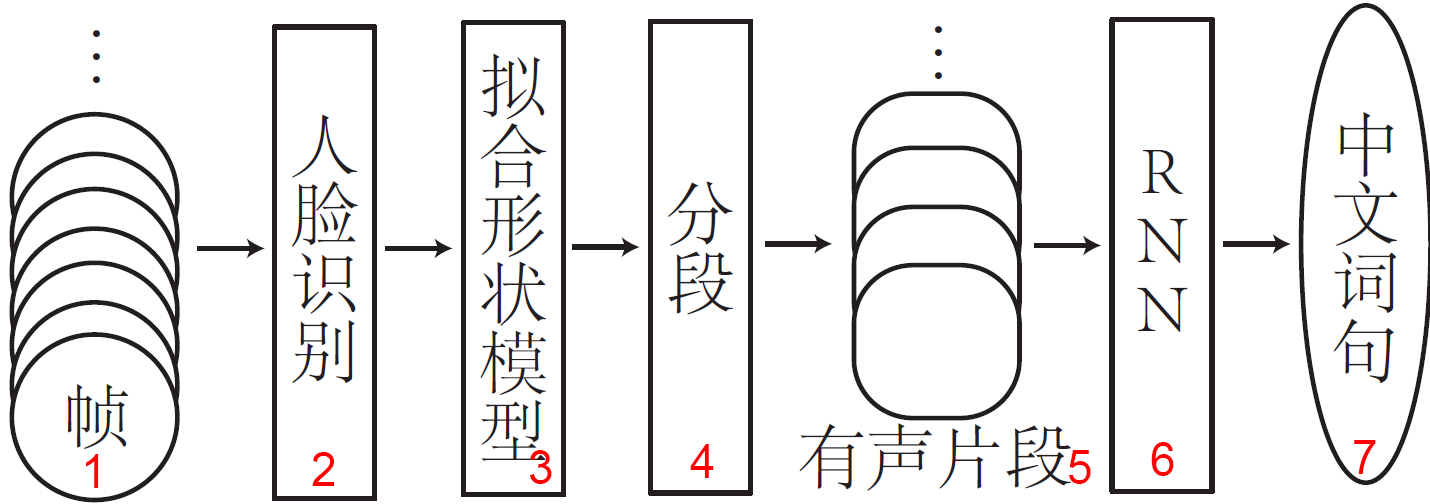 The architecture of the lipreading system. The corresponding English translations are: 1. frames 2. face detection 3. fitting contour model 4. segmentation 5. vocal segment 7. Chinese words and sentences
The architecture of the lipreading system. The corresponding English translations are: 1. frames 2. face detection 3. fitting contour model 4. segmentation 5. vocal segment 7. Chinese words and sentences
The frames in the video are sent into face detection and face alignment module. Now the original video has been converted into lip feature sequences, which will be subsequently segmented into two types of segments, namely vocal segments and silent segments. In vocal segments, the speaker in the original video is speaking something; while in silent segments, the speaker in the original video stays silent. The vocal segments are sent into the RNN to be categorized, which outputs the corresponding Chinese words and sentences.
-
Using HOG + SVM to achieve face detection
The implementation of face detection is provided by dlib. The robustness of the face detection module has been verified with experiments.
-
Using gradient boosting and random forest regression to achieve face alignment and lip feature extraction
The basic idea of face alignment is acquired from the following article:
Kazemi, Vahid, and Josephine Sullivan. “One millisecond face alignment with an ensemble of regression trees.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
The implementation of face alignment is provided by dlib as well. The robustness of the face alignment module has been verified with experiments.
-
Using PCA to extract numerical feature from lip feature segments, which is subsequently used to segment the entire lip feature sequence
It would be more desirable if we can quantify the distance between an unknown lip segment and a silent segment. Using the value and the gradient of the value of the distance, we can segment the lip feature segment more accurately.
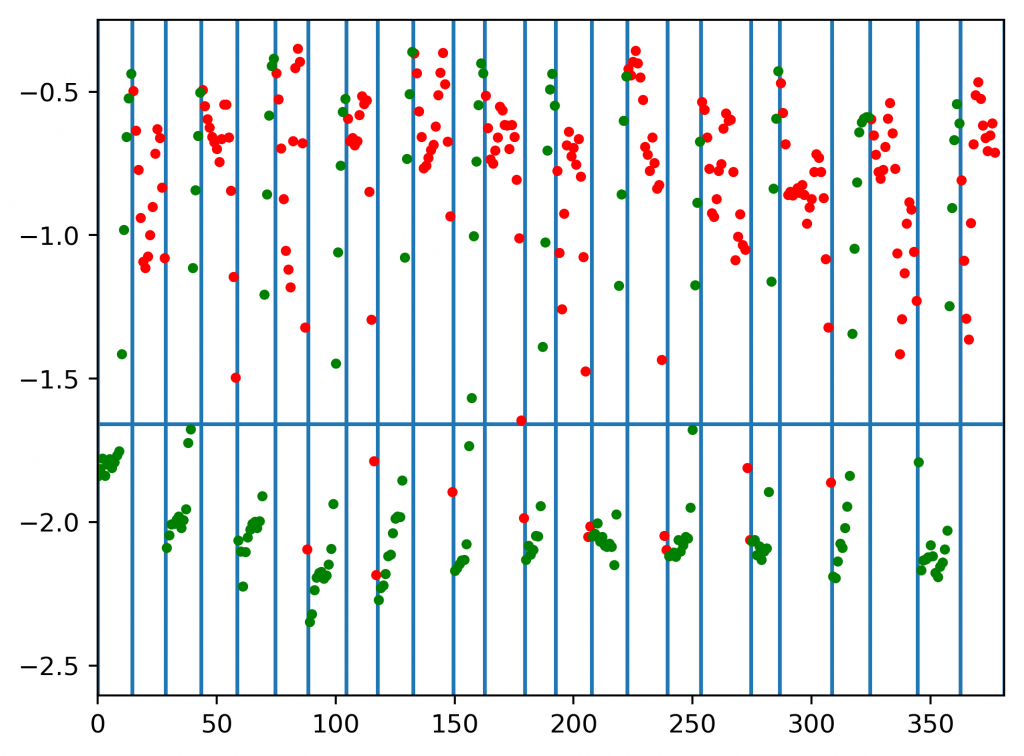 A figure that demonstrates the result of automatic lip segmentation. The horizontal axis indicates the index of lip feature segments in the video; the vertical axis indicates the common logarithm of the distance between a segment and a silent segment. Green dots indicate that the segment is a silent segment; red dot indicate that the segment is a vocal segment. The vertical lines are the segmentation result generated by the automatic lip segmentation method.
A figure that demonstrates the result of automatic lip segmentation. The horizontal axis indicates the index of lip feature segments in the video; the vertical axis indicates the common logarithm of the distance between a segment and a silent segment. Green dots indicate that the segment is a silent segment; red dot indicate that the segment is a vocal segment. The vertical lines are the segmentation result generated by the automatic lip segmentation method.In our experiment, the accuracy of lip feature segmentation of the validation set is 95.21%.
-
Using LSTM network to achieve lipreading
In our experiment, the accuracy of the LSTM network on the traning set is 97.04%; the accuracy of the LSTM network on the validation set is 87.50%.
Corpus
Due to the fact that public Chinese corpus materials are pretty rare, the corpus is recorded by the author himself. There is only one speaker, which means all the experiments are speaker-dependent. The corpus contains three 2-character words, three 3-character words and three 4-character words. In the training set, each word is repeated at least 10 times. In the validation set, each word is repeated exactly 2 times.
Overall Performance
If lipreading is accurate if and if only both segmentation result and LSTM output are correct, the system achieves 84.85% accuracy on training set, and 91.67% accuracy on validation set.
If the accuracy is calculated using the angle between word vectors, the angle for training set is 10.07◦, and the angle for validation set is 16.10◦.
Conclusion
- Shallow LSTM network works well on small-scale Chinese lipreading problem
- The overall performance of the system indicates that it is able to address real world Chinese lipreading problems
- Due to the limitation of equipment and corpus, only small scale experiments are carried out. Furthur large scale experiments are required to examine the capability of the system.