Generating Link Preview
25 Mar 2020Link previews can help one understand a link. It is also much more beautiful than a simple hyperlink. Let’s discuss how to generate these beautiful previews for a web page. The resulting preview block looks like this:
Parsing metadata in header
As it is shown below, there are four major elements in a link preview.
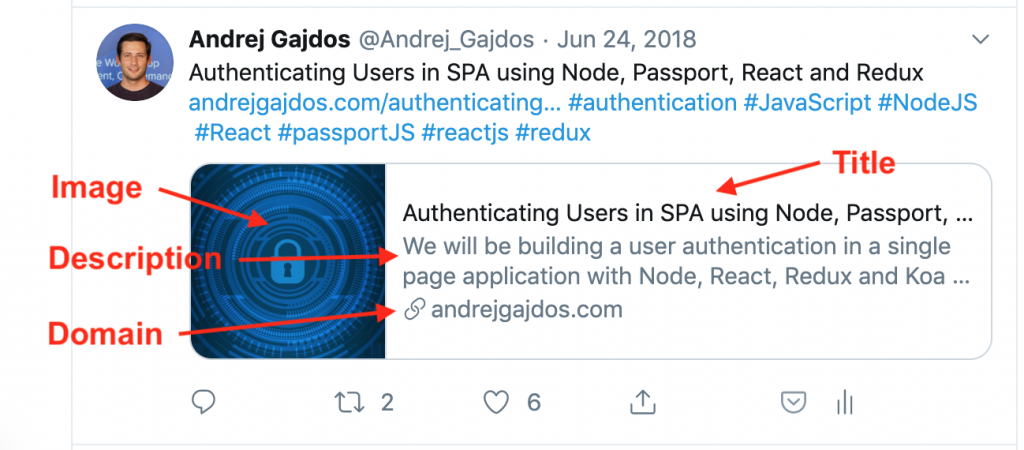
-
Title
Title can be specified with
<meta property="og:title" content="title">tags. If this tag cannot be found, we can also extract it from<title></title>tags. -
Image
A profile image can be found in
<meta property="og:image" content="img.jpg">tags. If this tag cannot be found, we can use the shortcut icon of the website or use the first image in the web page instead. -
Description
A short description can be found in
<meta property="og:description" content="des">tags. If this tag cannot be found, we use the first paragraph<p></p>instead. -
Domain
The website URL is specified in
<meta property="og:url" content="http://example.com">tags. If this tag cannot be found, we use the input URL instead.
The Python section gives the program to automatically generate a link preview provided a link. It depends on the stylesheet in the CSS section. Also, the script shown in the Javascript section needs to be appended to the end of the document to ensure a correct aspect ratio.
Python
Notes
- the calendar character (📅) may not be correctly displayed in PyCharm.
- In HTML5, the meta tag does not need to be closed with slash. However, if we use
html.parserinBeautifulSoup, it will not be able to parse the tags correctly. We need to usehtml5libparser instead.
import urllib3
import sys
from bs4 import BeautifulSoup
from html import unescape, escape
from termcolor import colored
from urllib.parse import urlparse, urljoin, urlunparse
from datetime import datetime
def print_warning(*args, **kwargs):
print(*[colored(s, 'red') for s in args], **kwargs)
def print_decision(*args, **kwargs):
print(*[colored(s, 'green') for s in args], **kwargs)
hdr = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding': 'none',
'Accept-Language': 'en-US,en;q=0.8',
'Connection': 'keep-alive'}
urlInfo = urlparse(sys.argv[1])
if len(urlInfo.scheme) == 0 or len(urlInfo.netloc) == 0:
raise RuntimeError('please use complete URL starting with http:// or https://')
urlBase = urlInfo.scheme + '://' + urlInfo.netloc
http = urllib3.PoolManager()
request = http.request('GET', sys.argv[1], headers=hdr)
content = request.data
soup = BeautifulSoup(content, 'html5lib')
result = {}
def resolve_title():
global soup
tag = soup.find('meta', attrs={'property' : 'og:title'})
if tag is not None and 'content' in tag.attrs:
print_decision('title acquired from meta \"og:title\"')
return tag['content']
tag = soup.find('title')
if tag is not None:
print_decision('title acquired from title tag')
return tag.text
print_warning('unable to extract title from page')
return None
def resolve_image():
global soup, urlBase
tag = soup.find('meta', attrs={'property' : 'og:image'})
if tag is not None and 'content' in tag.attrs:
print_decision('image acquired from meta \"og:image\"')
return urljoin(urlBase, tag['content'])
tag = soup.find('link', attrs={'rel' : 'shortcut icon'})
if tag is not None and 'href' in tag.attrs:
print_decision('image acquired from shortcut icon')
return urljoin(urlBase, tag['href'])
tag = soup.find('img')
if tag is not None and 'src' in tag.attrs:
print_decision('image acquired from the first image in page')
return urljoin(urlBase, tag['src'])
print_warning('unable to resolve image for page')
return None
def resolve_description():
global soup
tag = soup.find('meta', attrs={'property' : 'og:description'})
if tag is not None and 'content' in tag.attrs:
print_decision('description acquired from meta \"og:description\"')
return tag['content']
body = soup.find('body')
if body is not None:
tag = body.find('p')
if tag is not None:
print_decision('description acquired from first paragraph')
return tag.text
print_warning('unable to resolve description for page')
return None
def resolve_domain():
global soup, urlInfo
tag = soup.find('meta', attrs={'property' : 'og:url'})
if tag is not None and 'content' in tag.attrs:
ogUrlInfo = urlparse(tag['content'])
if len(ogUrlInfo.netloc) > 0:
print_decision('domain name acquired from meta \"og:url\"')
return ogUrlInfo.netloc
print_decision('domain name acquired from input')
return urlInfo.netloc
def show_result():
global result
for key, val in result.items():
print(key + ': ' + val)
def build_link_preview():
global result
template = r'''
<div class="div-link-preview">
<div class="div-link-preview-col div-link-preview-col-l">
<img class="div-link-preview-img" src="{img_link:}">
</div>
<div class="div-link-preview-col div-link-preview-col-r">
<div style="display: block; height: 100%; padding-left: 10px;">
<div class="div-link-preview-title"><a href="{page_link:}">{page_title:}</a></div>
<div class="div-link-preview-content">{page_description:}</div>
<div class="div-link-preview-domain">
<span style="font-size: 80%;">📅</span> {proc_date:}
<span style="font-size: 80%; margin-left: 20px;">🔗</span> {page_domain:}</div>
</div>
</div>
</div>
'''
return template.format(
img_link=result['image'],
page_title=result['title'],
page_link=result['link'],
page_description=result['description'],
page_domain=result['domain'],
proc_date=result['access_date']
)
result['title'] = resolve_title()
result['image'] = resolve_image()
result['description'] = resolve_description()
result['domain'] = resolve_domain()
result['link'] = sys.argv[1]
result['access_date'] = datetime.now().strftime('%b %-d, %Y')
show_result()
print('')
print(build_link_preview())
Output snapshot
(base) user@machine:~/website_jekyll_folder/_script$ python gen_link_preview.py https://medium.com/better-programming/link-previews-more-than-meets-the-eye-aa13c77c6d69
/home/alan/anaconda3/lib/python3.7/site-packages/urllib3/connectionpool.py:847: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecureRequestWarning)
title acquired from meta "og:title"
image acquired from meta "og:image"
description acquired from meta "og:description"
domain name acquired from meta "og:url"
title: Link Previews — More than Meets the Eye
image: https://miro.medium.com/max/1200/0*f6Vz4GodmmZIUtP6
description: Ever wondered how this preview is generated?
domain: medium.com
link: https://medium.com/better-programming/link-previews-more-than-meets-the-eye-aa13c77c6d69
access_date: Mar 25, 2020
<div class="div-link-preview">
<div class="div-link-preview-col div-link-preview-col-l">
<img class="div-link-preview-img" src="https://miro.medium.com/max/1200/0*f6Vz4GodmmZIUtP6">
</div>
<div class="div-link-preview-col div-link-preview-col-r">
<div style="display: block; height: 100%; padding-left: 10px;">
<div class="div-link-preview-title"><a href="https://medium.com/better-programming/link-previews-more-than-meets-the-eye-aa13c77c6d69">Link Previews — More than Meets the Eye</a></div>
<div class="div-link-preview-content">Ever wondered how this preview is generated?</div>
<div class="div-link-preview-domain">
<span style="font-size: 80%;">📅</span> Mar 25, 2020
<span style="font-size: 80%; margin-left: 20px;">🔗</span> medium.com</div>
</div>
</div>
</div>
CSS
.div-link-preview {
margin-left: auto;
margin-right: auto;
border-radius: 10px;
border: 2px solid #C0C0C0;
overflow: hidden;
width: 90%;
margin-bottom: 10px;
}
.div-link-preview:after {
content: "";
display: table;
clear: both;
}
.div-link-preview-col {
float: left;
}
.div-link-preview-col-l {
width: 18%
}
.div-link-preview-col-r {
width: 80%;
padding-top: 5px;
}
.div-link-preview-img {
width: 100%;
height: 100%;
object-fit: cover;
}
.div-link-preview-content::-webkit-scrollbar {
width: 0px;
background: transparent; /* Chrome/Safari/Webkit */
}
.div-link-preview-title {
display: block;
margin-right: auto;
width: 98%;
font-weight: bold;
overflow: hidden;
text-overflow: ellipsis;
white-space: nowrap;
color: #101010;
text-decoration: underline;
}
.div-link-preview-title a{
color: #101010;
text-decoration: underline;
}
.div-link-preview-content {
display: block;
font-size: small;
height: 58%;
overflow: auto;
color: #606060;
}
.div-link-preview-domain {
padding-right: 2%;
display: block;
font-weight: bold;
color: #808080;
text-align: right;
font-size: 80%;
font-family: Arial, Helvetica, sans-serif;
}
Javascript
<script>
function adjustLinkPreviewHeight(){
console.log("running!");
var cats = document.querySelectorAll('.div-link-preview');
//console.log(cats.length);
for (var i = 0; i < cats.length; i++) {
var left = cats[i].querySelector('.div-link-preview-col-l');
var right = cats[i].querySelector('.div-link-preview-col-r');
var width = left.clientWidth;
cats[i].style.height = width + "px";
left.style.height = width + "px";
right.style.height = width + "px";
}
}
adjustLinkPreviewHeight();
</script>