Knuth–Morris–Pratt Algorithm
31 Jul 2018According to the definition on wikipedia, pattern matching is defined as follows:
In computer science, pattern matching is the act of checking a given sequence of tokens for the presence of the constituents of some pattern. In contrast to pattern recognition, the match usually has to be exact “either it will not be a match”. The patterns generally have the form of either sequences or tree structures. Uses of pattern matching include outputting the locations (if any) of a pattern within a token sequence, to output some component of the matched pattern, and to substitute the matching pattern with some other token sequence (i.e., search and replace).
The Knuth–Morris–Pratt algorithm (a.k.a. KMP algorithm) is a type of efficient pattern matching algorithm to find match of pattern string in main string. Compared to the naive pattern matching algorithm, when the scale of the matching problem is large, its time complexity is considerably less.
Notations
- \(M\) denotes main string, and \(P\) denotes the pattern string.
- \(\lvert S \rvert\) denotes the size of the string \(S\). For common pattern matching problems, it can be seen that \(\lvert M \rvert > 0, \lvert M \rvert \geq \lvert P\rvert\).
- \(S[i]\) denotes the $(i + 1)$th element of the string \(S\). It can be seen that \(i \in [0, \lvert S\rvert)\) (to accord with the notation in computer systems).
- \(S[i:j]\ (j \geq i)\) denotes the substring of the string \(S\). It is lead by the ith element in \(S\), and its length is \(j - i - 1\). If \(i =j\), it represents a null string.
Sample Test Case
To find out the property of pattern matching algorithms, we are using the following test case, where
- \(M\) = “ABCADABCAD”
- \(P\) = “ABCAF”
We not only want to analyze the time complexity of different pattern matching algorithms, but we also want to program generalized algorithms for practice. Therefore, we always provide the offset option in our algorithm. In complexity analysis, however, we will consider that offset = 0.
The Naive Pattern Matching Algorithm
The naive pattern matching algorithm is really easy to derive. There are two indices i and j, and we can compare the pattern string with the main string with a nested loop as follows:
constexpr const size_t npos = static_cast<size_t>(-1);
template<typename String>
inline size_t StringFind(const String &main, const String &ptn, size_t offset = 0) {
auto mainSize = main.size();
auto ptnSize = ptn.size();
if (mainSize == 0 || offset >= mainSize - 1|| ptnSize > mainSize - offset) {
return npos;
}
if (ptnSize == 0) {
return 0;
}
for (size_t i = offset; i < mainSize - ptnSize; ++i) {
bool match = true;
size_t new_i = i;
for (size_t j = 0; j < ptnSize; ++j) {
if (main[new_i++] != ptn[j]) {
match = false;
break;
}
}
if (match) {
return i;
}
}
return npos;
}
It can be seen that the time complexity of naive pattern matching is \(O(\lvert M\rvert \cdot \lvert N\rvert)\), in worst case. When the scale of problem grows, the complexity increases in a quadratic manner, which is very undesirable.
Impove Naive Pattern Matching
If we dig deep into the procedure of naive pattern matching algorithm, we should be able to find out that there are many unnecessary comparisons. Take our test case as an example, when the algorithm starts, the state of the program can be represented by the following figure:
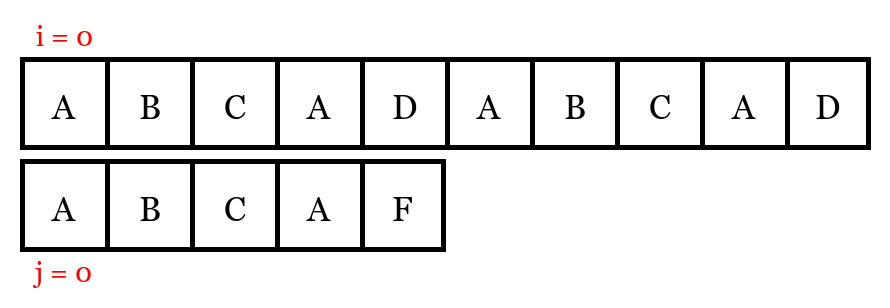 The state of naive pattern matching algorithm when it starts.
The state of naive pattern matching algorithm when it starts.
When \(i = 0, new_i = 4\) and \(j = 4\), a mismatch is found, then \(i\) is incremented by one, and \(j\) is reset to zero, and the inner comparison loop starts over again.
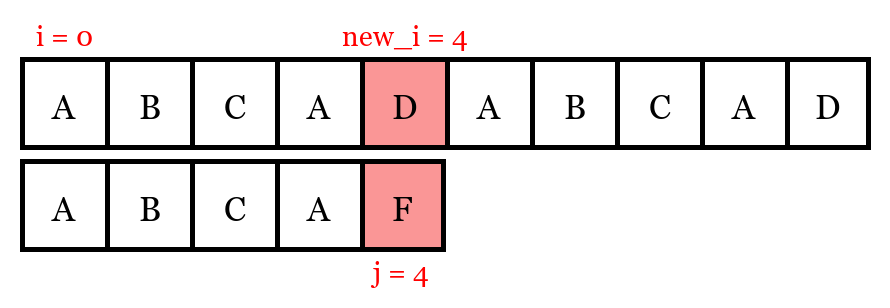 When \(new_i = 3\) and \(j = 3\), the first mismatch is found.
When \(new_i = 3\) and \(j = 3\), the first mismatch is found.
The new state of algorithm after the first mismatch is depicted as follows:
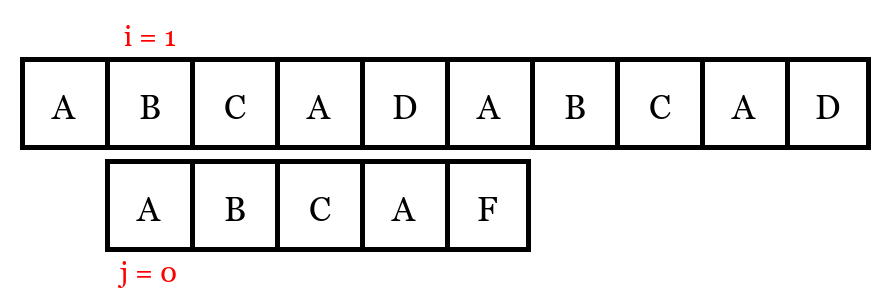 The new state of the naive pattern matching algorithm after the first mismatch is found.
The new state of the naive pattern matching algorithm after the first mismatch is found.
We can immediately realize that we do not have to start over from \(i = 1\), due to the fact that letter A only appeared twice in \(M[0: 5]\), so there is no way for us to declare a matching pattern for those $i$’s, where \(M[i] \neq\) A. The next value of \(i\) that is possible to have a matching pattern is \(i = 4\). That is to say, after each mismatch, we do not have to reset \(i\) value according to the outer loop. We can actually leave \(i = new_i\), and change the \(j\) value accordingly to complete pattern matching. This will boost effiency greatly.
How to find the next \(j\)?
For the situation illustrated above, we know that \(M[0:4] = P[0:4]\), but \(M[4] \neq P[4]\). Assume that we have complete knowledge about the pattern string before pattern matching. That is, we know that there are only two A’s in the pattern string, which indicates that there will also be two A’s in \(M[0:4]\). We have already known that state \(i = 0, j = 0\) will not yield a positive result. If there is still a match for \(i \in [0, 5)\), there is only one possibility left: \(i = 4, j = 1\), which is illustrated as follows.
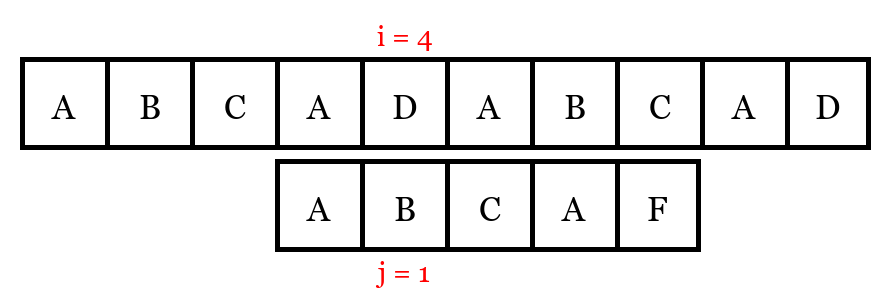 The next possible state for a match.
The next possible state for a match.
Because we know that \(P[0] = P[3]\) and \(P[3] = M[3]\), we can conclude that \(M[3] = P[0]\). We can directly start comparing \(M[4]\) and \(P[1]\). By doing this, we can eliminate a lot of redundant computation.
Now the problem shows itself: given a new state, how to find the next $j$? Assume that during the matching loop, we find out that the $i$th element of \(M\) is not equal to the $j$th element of \(P\), that is:
\[\begin{align}\label{base1} M[i] &\neq P[j], \end{align}\] \[\begin{align}\label{base2} M[i-j:i] &= P[0:j]. \end{align}\]Rewrite \((\ref{base2})\) backwards, given \(k \in (0, j)\), we have
\[\begin{align}\label{base3} M[i-k:i] = P[j-k:j]. \end{align}\]We can avoid comparing the first \(k\) elements and simplify pattern matching computation if we can find \(k\), such that
\[\begin{align}\label{base4} M[i-k : i] = P[0:k]. \end{align}\]We only need to compare the elements rest now (i.e. compare \(P[k:\lvert P\rvert]\) and \(M[i:i + \lvert P\rvert - k]\)), if they match, then we can assert that pattern string \(P\) appears in main string \(M\). Combing (\ref{base3}) and (\ref{base4}), it can be seen that we need to solve for $k$, where
\[\begin{align}\label{base5} P[0:k] = P[j-k:j]. \end{align}\]It can be seen that the next \(j\) is a solution of \(k\) in equation (\ref{base5}), which only depends on the pattern stirng.
Sometimes we might be unable to find a solution that satisfy \(k \in (0, j)\), in this case we can proof that there will be no match for all \(i\)’s in \((i-j,i)\) by contradiction. If there is a match for \(i = i^\prime \in (i-j,i)\), we know that
\[\begin{align} M[i^\prime:i] = P[0 : j - (i - i^\prime)]. \end{align} \]But according to \((\ref{base3})\), it can be seen that
\[\begin{align} M[i^\prime:i] = P[j - (i - i^\prime) : j], \end{align}\]which gives
\[\begin{align} P[0 : j - (i - i^\prime)] = P[j - (i - i^\prime) : j]. \end{align}\]Note that \(i - i^\prime \in (0,j)\), we have found a \(k \in (0, j)\), which contradicts the fact that we cannot find one. Therefore, there will be no match for all \(i\)’s in \((i-j,i)\). We need to start the comparison to leave \(i\) untouched, and let \(j = 0\). Now, the next \(j\) is zero, and for consistency, we can use \(k = 0\) to denote this situation. Note that when a mismatch is found and \(j = 0\), the first elements do not match, and \(k\) does not exist.
Now, given \(j\), how to compute \(k\) efficiently? There is a recursion foumula that can help us a little bit.
\[\begin{align} P[0:k] = P[j-k : j], \end{align}\]and that
\[\begin{align} P[k] = P[j], \end{align}\]we can conclude that \(P[0:k+1] = P[j - k : j + 1] = P[ (j + 1) - (k + 1) : j+1]\). That is to say, if the the next \(j\) value for \(j\) is \(k\), and that \(P[k] = P[j]\), we can conclude that the next \(j\) value for \(j + 1\) is \(k + 1\).
Another observation can help us find the \(k\) value when the recursion formula does not apply. If are given \(j\) and \(k\), such that
\[\begin{align}\label{nextbase1} P[0:k] = P[j-k : j], \end{align}\]and that
\[\begin{align} P[k] \neq P[j], \end{align}\]if we denote the \(k\) value when \(j = k\) by \(k^{\prime}\), and that if \(k^{\prime} > 0\), it can be seen that
\[\begin{align}\label{nextbase2} P[0:k^{\prime}] = P[k - k^{\prime}:k]. \end{align}\]Combining \((\ref{nextbase1})\) and \((\ref{nextbase2})\), we have
\[\begin{align} P[0:k^{\prime}] = P[k - k^{\prime}:k] = P[j - k + (k - k^{\prime}) : j] = P[j - k^{\prime}:j]. \end{align}\]Now, if \(P[j] = P[k^{\prime}]\), we can know that \(P[0:k^{\prime} + 1] = P[(j+1)-(k^{\prime} + 1) : j + 1]\), which indicates that the \(k\) value for \(j+1\) is \(k^{\prime} + 1\). If \(P[j] \neq P[k^{\prime}]\), denote the \(k\) value when \(j = :k^{\prime}\) by \(k^{\prime\prime}\). If \(k^{\prime\prime} > 0\), we will have
\[\begin{align}\label{nextbase3} P[0:k^{\prime\prime}] = P[k^{\prime} - k^{\prime\prime} : k^{\prime}]. \end{align}\]Combining \((\ref{nextbase1})\), \((\ref{nextbase2})\) and \((\ref{nextbase3})\), we have
\[\begin{multline} P[0:k^{\prime\prime}] = P[k^{\prime} - k^{\prime\prime} : k^{\prime}] = P[k - k^{\prime} + (k^{\prime} - k^{\prime\prime}):k] \\ = P[k - k^{\prime\prime} : k] = P[j - k + (k - k^{\prime\prime}) : j] = P[j - k^{\prime\prime} : j]. \end{multline}\]Therefore if \(P[j] = P[k^{\prime\prime}]\), then we can conclude that the \(k\) value for \(j+1\) is \(k^{\prime\prime} + 1\). It can be seen that this can be done repeatedly, until some \(k^\prime\) equals to zero.
Using all the observations above, the algorithm that builds the \(k\) value table is as follows.
// use this value to denote an invalid k value
constexpr const size_t npos = static_cast<size_t>(-1);
template<typename String>
inline vector<size_t> GetNextJ(const String &str) {
vector<size_t> result;
if (str.empty()) {
return result;
}
result.resize(str.size());
// the k value for j = 0 does not exist
result[0] = npos;
const size_t strSize = str.size();
// stores the owner of the current k value
size_t j = 0;
// k stores the k value for j, or the next guessd k value
// for j + 1
size_t k = npos;
// each loop, we verify whether k is a correct guess of the
// k value of j + 1
while(j < strSize - 1){
if (k == npos) {
// if k does not exist, we know
// that we have to start comparing at j = 0
// that is, the k value for j + 1 is 0
result[++j] = 0;
// k is set to 0, because if str[j] = str[0] in next loop,
// we can find the k value in a more consistent manner
k = 0;
}
else if (str[j] == str[k]) {
// test whether the current k is a correct guess
result[++j] = ++k;
}
else {
// if the guessed value is incorrect
// use the observation above
k = result[k];
}
}
return result;
}
The Knuth–Morris–Pratt Algorithm
Now that we have known how to find the next \(j\) value, we can come up with the Knuth–Morris–Pratt algorithm easily.
// use this value to denote an invalid k value
constexpr const size_t npos = static_cast<size_t>(-1);
template<typename String>
inline vector<size_t> GetNextJ(const String &str) {
vector<size_t> result;
if (str.empty()) {
return result;
}
result.resize(str.size());
// the k value for j = 0 does not exist
result[0] = npos;
const size_t strSize = str.size();
// stores the owner of the current k value
size_t j = 0;
// k stores the k value for j, or the next guessd k value
// for j + 1
size_t k = npos;
// each loop, we verify whether k is a correct guess of the
// k value of j + 1
while(j < strSize - 1){
if (k == npos) {
// if k does not exist, we know
// that we have to start comparing at j = 0
// that is, the k value for j + 1 is 0
result[++j] = 0;
// k is set to 0, because if str[j] = str[0] in next loop,
// we can find the k value in a more consistent manner
k = 0;
}
else if (str[j] == str[k]) {
// test whether the current k is a correct guess
result[++j] = ++k;
}
else {
// if the guessed value is incorrect
// use the observation above
k = result[k];
}
}
return result;
}
template<typename String>
inline size_t KMPStringFind(const String &main, const String &ptn, size_t offset= 0) {
auto mainSize = main.size();
auto ptnSize = ptn.size();
if (mainSize == 0 || offset >= mainSize - 1 || ptnSize > mainSize - offset) {
return npos;
}
if (ptnSize == 0) {
return 0;
}
auto nextJ = move(GetNextJ(ptn));
// initialize k with 0
size_t j = 0;
size_t i = offset;
while(i < mainSize) {
if (main[i] == ptn[j]) {
if (j == ptnSize - 1) {
return i - j; // the head position of the matching string
}
i++;
j++;
}
else {
// there is partial match between main string and
// the pattern string
// using the same approach in GetNextJ to find the next
// possible k value
j = nextJ[j];
if (j == npos) {
i++;
j++;
}
}
}
return npos;
}
// the first component indicates whether there is a match
template<typename String>
inline pair<bool, vector<size_t>> KMPStringFindAll(const String &main, const String &ptn, size_t offset = 0) {
pair<bool, vector<size_t>> result;
result.first = true;
auto mainSize = main.size();
auto ptnSize = ptn.size();
if (mainSize == 0 || offset >= mainSize - 1 || ptnSize > mainSize - offset) {
result.first = false;
return result;
}
if (ptnSize == 0) {
result.second.push_back(0);
return result;
}
auto nextJ = move(GetNextJ(ptn));
// initialize k with 0
size_t j = 0;
size_t i = offset;
while (i < mainSize) {
if (main[i] == ptn[j]) {
if (j == ptnSize - 1) {
result.second.push_back(i - j);
i = i - j + 1; // restart comparing at the next character after the match
j = 0; // restart comparing at the beginning
continue;
}
i++;
j++;
}
else {
// there is partial match between main string and
// the pattern string
// using the same approach in GetNextJ to find the next
// possible k value
j = nextJ[j];
if (j == npos) {
i++;
j++;
}
}
}
return result;
}
The time complexity of getting next j is \(O(\lvert P\rvert)\), and the complexity of finding the match is \(O(\lvert M\rvert)\) (for the first match version). The total time complexity of the KMP algorithm is \(O(\vert P\rvert + \lvert M\rvert)\). But it requires \(O(\lvert P\rvert)\) space overhead.
It can be one of the reasons why the STL does not apply this method in string::find, because in practice allocating space can introduce overhead, which can make the KMP version slower. (edited on May 14, 2019)
Acknowledgements
This article is greatly inspired by 孤~影’s work, which is in Chinese. He has given a very detailed description and illustration of the KMP algorithm. If you read Chinese, you are encouraged to enjoy his article.
Epilogue
It took me several days to figure out how the KMP algorithm works. I have seen many posts on the Internet that try to describe the process with diagrams, but I think diagrams are harder to be understood. Personally, I want to proof that it is a valid and efficient algorithm with rigorous argument. 孤~影’s work gave me an inspiration, besides using illustrations, he used mathematical expressions to describe how it works. I find it very easy to comprehend, so I derived all the following equalities from the formulae that he provided.
When it comes to algorithms, I think it is very important to throughly understand what is going on. It helps you memorize the algorithm, and you can even design new algorithms based on it. But none of these can be done without a tight grasp of existring algorithms themselves.
Appendix
I wrote a Python program to generate the illustrations. It is based on numpy and Pillow, the code is attached as follows.
from PIL import Image, ImageDraw, ImageFont
import numpy as np
class CharBlock:
char = '\0'
charColor = (0, 0, 0)
bgColor = (255, 255, 255)
desText = ''
desTextPos = 0 # 0 for up, 1 for down
desTextColor = (255, 0, 0)
class CharBlockListObj:
charBlocks = None
hasTop = False
hasBot = False
def __init__(self, charBlocks):
self.charBlocks = charBlocks
def __getitem__(self, item):
return self.charBlocks[item]
def __len__(self):
return len(self.charBlocks)
def GenCharBlockList(string):
result = []
for char in string:
charBlock = CharBlock()
charBlock.char = char
result.append(charBlock)
return result
def GenCharBlockListObj(lstCB):
hasTop = False
hasBot = False
lstObj = CharBlockListObj(lstCB)
for cb in lstCB:
if cb.desText != '':
if cb.desTextPos == 0:
hasTop = True
else:
hasBot = True
if hasTop and hasBot:
raise RuntimeError('invalid description line')
lstObj.hasTop = hasTop
lstObj.hasBot = hasBot
return lstObj
fontPath = 'C:/windows/fonts/georgia.ttf'
fontSize = 34
desFontSize = 28
charBlockInterval = 60
lineInterval = 10
desInterval = 5
sideInterval = (20, 20)
imgBackgroundColor = (255, 255, 255)
charBlockColor = (0, 0, 0)
charBlockLineWidth = 5
def GetMaxMainTextSize(lstCharBlockS, font):
maxWidth = -1
maxHeight = -1
testImg = Image.new('RGB', (10, 10))
draw = ImageDraw.Draw(testImg)
for lstCharBlock in lstCharBlockS:
for charBlock in lstCharBlock:
textSize = draw.textsize(charBlock.char, font)
maxWidth = max(maxWidth, textSize[0])
maxHeight = max(maxHeight, textSize[1])
return np.array((maxWidth, maxHeight), np.int)
def GetMaxDesTextSize(lstCharBlockS, font):
maxWidth = -1
maxHeight = -1
testImg = Image.new('RGB', (100, 100))
draw = ImageDraw.Draw(testImg)
for lstCharBlock in lstCharBlockS:
for charBlock in lstCharBlock:
textSize = draw.textsize(charBlock.desText, font)
maxWidth = max(maxWidth, textSize[0])
maxHeight = max(maxHeight, textSize[1])
return np.array((maxWidth, maxHeight), np.int)
def VecToTup(vec):
return tuple(vec.tolist())
def DrawRectangle(draw, topLeft, botRight, drawRight=False, lineWidth=charBlockLineWidth, lineColor=charBlockColor,
bgColor=imgBackgroundColor):
innerTopLeft = topLeft + np.array((lineWidth, lineWidth), np.int)
innerBotRight = botRight + np.array((0, -lineWidth), np.int)
if drawRight:
innerBotRight = botRight + np.array((-lineWidth, -lineWidth), np.int)
draw.rectangle((VecToTup(topLeft), VecToTup(botRight)), lineColor)
draw.rectangle((VecToTup(innerTopLeft), VecToTup(innerBotRight)), bgColor)
# draw a series of list of charBlock
def DrawCharBlocks(lstCharBlockS):
# load font
mainFont = ImageFont.truetype(fontPath, fontSize)
desFont = ImageFont.truetype(fontPath, desFontSize)
# find text height
mainTextSize = GetMaxMainTextSize(lstCharBlockS, mainFont)
desTextSize = GetMaxDesTextSize(lstCharBlockS, desFont)
# calculate the size of a charBlock
charBlockSize = np.array((mainTextSize[0] + charBlockInterval, mainTextSize[1] + charBlockInterval), np.int)
desFontHeight = desTextSize[1]
# find the maximum lentgh of charBlock series
lengthList = [(len(charBlockList)) for charBlockList in lstCharBlockS]
maxCharBlockSLength = max(lengthList)
# calculate the width of the image
imgWidth = sideInterval[0] * 2 + maxCharBlockSLength * charBlockSize[0]
imgHeight = sideInterval[1] * 2 + charBlockSize[1] * len(lstCharBlockS) + (len(lstCharBlockS) - 1) * lineInterval
for lstCharBlock in lstCharBlockS:
if lstCharBlock.hasTop or lstCharBlock.hasBot:
imgHeight += desFontHeight + desInterval
# generate picture
img = Image.new('RGB', (imgWidth, imgHeight))
draw = ImageDraw.Draw(img)
draw.rectangle(((0, 0), (imgWidth, imgHeight)), imgBackgroundColor)
lineTopLeft = np.array(sideInterval, np.int)
desTextCharBlockOffset = np.array((0, desFontHeight + desInterval), np.int)
charBlockWidthVec = np.array((charBlockSize[0], 0), np.int)
realBlockSize = charBlockSize + np.array((charBlockLineWidth, 0), np.int)
desUpperOffset = np.array((0, -desInterval - desTextSize[1]), np.int)
desLowerOffset = np.array((0, desInterval + charBlockSize[1]), np.int)
#zeroVec = np.zeros(2, np.int)
globalCharBlockHeadPos = lineTopLeft
for ind, lstCharBlock in enumerate(lstCharBlockS):
# draw block
'''
heightOffset = 0
if ind > 0:
heightOffset = (desTextSize[1] * 2 + desInterval * 2 + charBlockSize[1] + lineInterval) * ind
'''
heightIncrement = charBlockSize[1] + lineInterval
charBlockHeadPos = np.copy(globalCharBlockHeadPos)
# align charBlockHeadPos, calculate height increment
if lstCharBlock.hasTop:
charBlockHeadPos += desTextCharBlockOffset
heightIncrement += desTextCharBlockOffset[1]
elif lstCharBlock.hasBot:
heightIncrement += desTextCharBlockOffset[1]
for i in range(len(lstCharBlock)):
myCharBlockHeadPos = charBlockHeadPos + i * charBlockWidthVec
myCharBlockBRPos = myCharBlockHeadPos + charBlockSize
# compute main text pos
textSize = np.array(draw.textsize(lstCharBlock[i].char, mainFont), np.int)
offsetRect = np.round((realBlockSize - textSize) / 2).astype(np.int)
if i == len(lstCharBlock) - 1: offsetRect = np.round((charBlockSize - textSize) / 2).astype(np.int)
textPos = myCharBlockHeadPos + offsetRect
# draw rectangle
drawRight = False
if i == len(lstCharBlock) - 1: drawRight = True
if lstCharBlock[i].char != ' ':
DrawRectangle(draw, myCharBlockHeadPos, myCharBlockBRPos, drawRight, charBlockLineWidth, charBlockColor,
lstCharBlock[i].bgColor)
# draw main text
draw.text(textPos, lstCharBlock[i].char, lstCharBlock[i].charColor, mainFont)
if lstCharBlock[i].desText != '':
# compute des text pos
desTextTopLeft = myCharBlockHeadPos + desUpperOffset
if lstCharBlock.hasBot:
desTextTopLeft = myCharBlockHeadPos + desLowerOffset
desTextSize = draw.textsize(lstCharBlock[i].desText, desFont)
widthShift = np.array((round((charBlockSize[0] + charBlockLineWidth - desTextSize[0]) / 2), 0), np.int)
if i == len(lstCharBlock) - 1: widthShift = np.array(
(round((charBlockSize[0] - desTextSize[0]) / 2), 0), np.int)
draw.text(desTextTopLeft + widthShift, lstCharBlock[i].desText, lstCharBlock[i].desTextColor, desFont)
globalCharBlockHeadPos[1] += heightIncrement
return img
def GenLstCharBlockS(strLst):
basicList = [GenCharBlockList(string) for string in strLst]
for ind, lst in enumerate(basicList):
for i in range(len(lst)):
lst[i].desTextPos = ind % 2
return basicList
def GenLstCharBlockSObj(lstCharBlockS):
result = [GenCharBlockListObj(lstCBS) for lstCBS in lstCharBlockS]
return result
def SaveCharBlocksImg(lstCharBlockS, filename):
img = DrawCharBlocks(lstCharBlockS)
with open(filename, 'wb') as outfile:
img.save(outfile)
mismatchColor = (250, 150, 150)
# naive-1
strLst = ['ABCADABCAD', 'ABCAF']
lstCBS = GenLstCharBlockS(strLst)
lstCBS[0][0].desText = 'i = 0'
lstCBS[1][0].desText = 'j = 0'
lstCBSObj = GenLstCharBlockSObj(lstCBS)
SaveCharBlocksImg(lstCBSObj, 'naive-1.png')
# naive-2
strLst = ['ABCADABCAD', ' ABCAF']
lstCBS = GenLstCharBlockS(strLst)
lstCBS[0][1].desText = 'i = 1'
lstCBS[1][1].desText = 'j = 0'
lstCBSObj = GenLstCharBlockSObj(lstCBS)
SaveCharBlocksImg(lstCBSObj, 'naive-2.png')
# naive-3
strLst = ['ABCADABCAD', 'ABCAF']
lstCBS = GenLstCharBlockS(strLst)
lstCBS[0][0].desText = 'i = 0'
lstCBS[0][4].desText = 'new_i = 4'
lstCBS[0][4].bgColor = mismatchColor
lstCBS[1][4].desText = 'j = 4'
lstCBS[1][4].bgColor = mismatchColor
lstCBSObj = GenLstCharBlockSObj(lstCBS)
SaveCharBlocksImg(lstCBSObj, 'naive-3.png')
# naive-4
strLst = ['ABCADABCAD', ' ABCAF']
lstCBS = GenLstCharBlockS(strLst)
lstCBS[0][4].desText = 'i = 4'
lstCBS[1][4].desText = 'j = 1'
lstCBSObj = GenLstCharBlockSObj(lstCBS)
SaveCharBlocksImg(lstCBSObj, 'naive-4.png')
# naive-5
strLst = ['ABCDEFGHI', 'ABCDF']
lstCBS = GenLstCharBlockS(strLst)
lstCBS[0][4].desText = 'i = 4'
lstCBS[1][4].desText = 'j = 4'
lstCBS[0][4].bgColor = mismatchColor
lstCBS[1][4].bgColor = mismatchColor
lstCBSObj = GenLstCharBlockSObj(lstCBS)
SaveCharBlocksImg(lstCBSObj, 'naive-5.png')
Today I would definitely not use Python to write a graph generation program like this. Maybe I would consider using tikz. (edited on May 14, 2019)